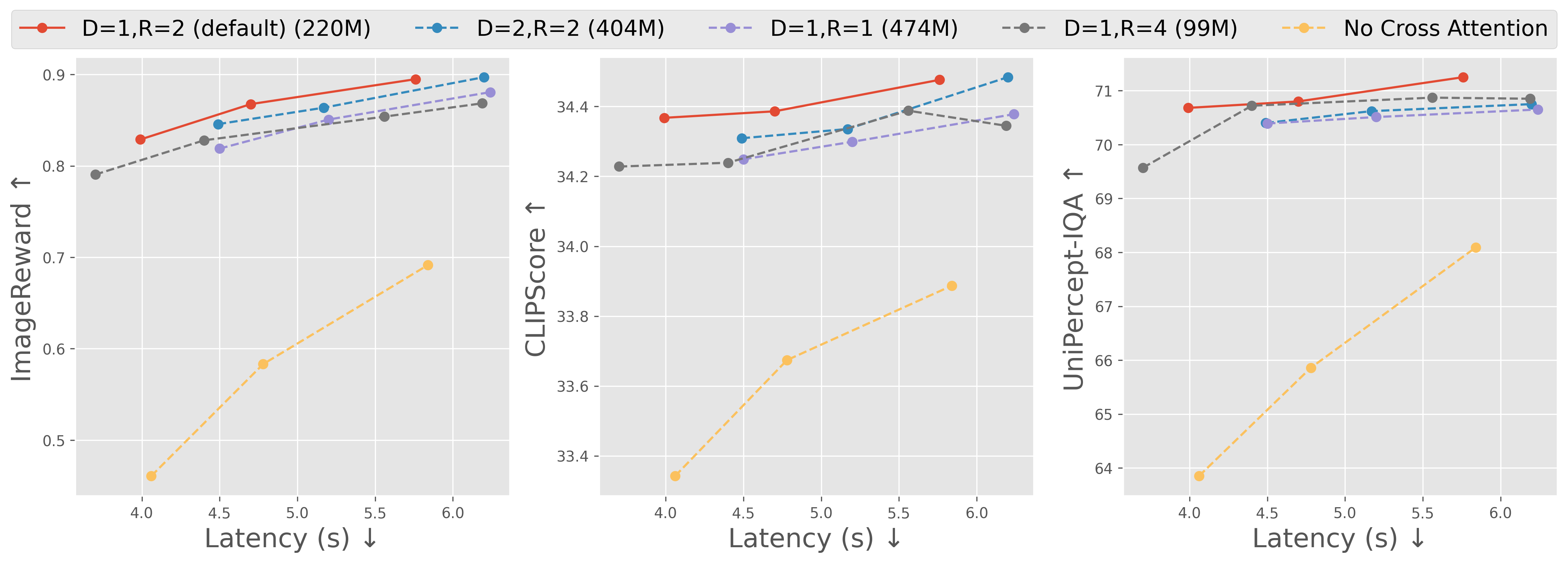
A point in the trajectory is the feature averaged over all tokens in a step. Left: heatmap of pairwise cosine similarity; Right: t-SNE visualization
Motivation
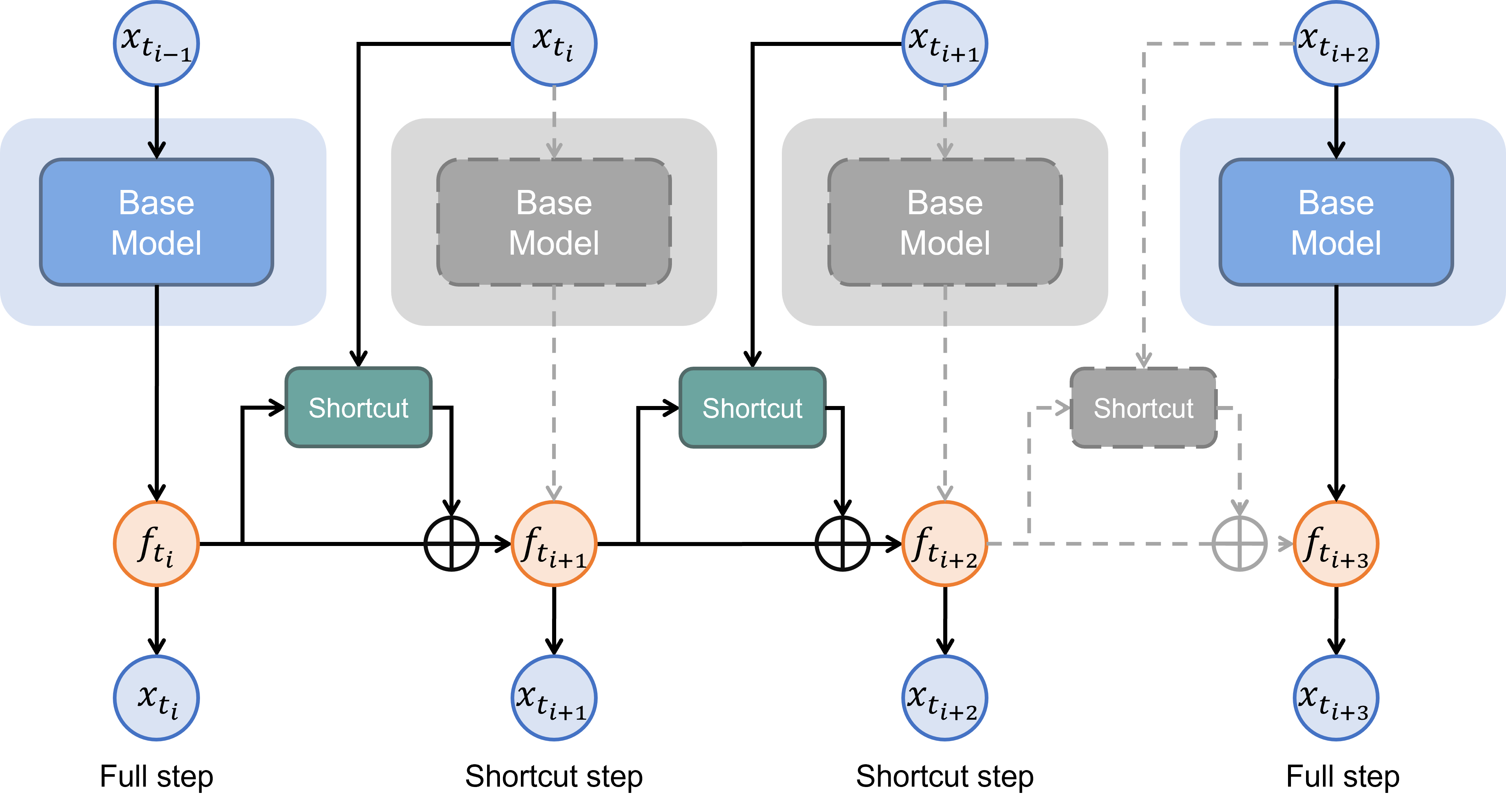
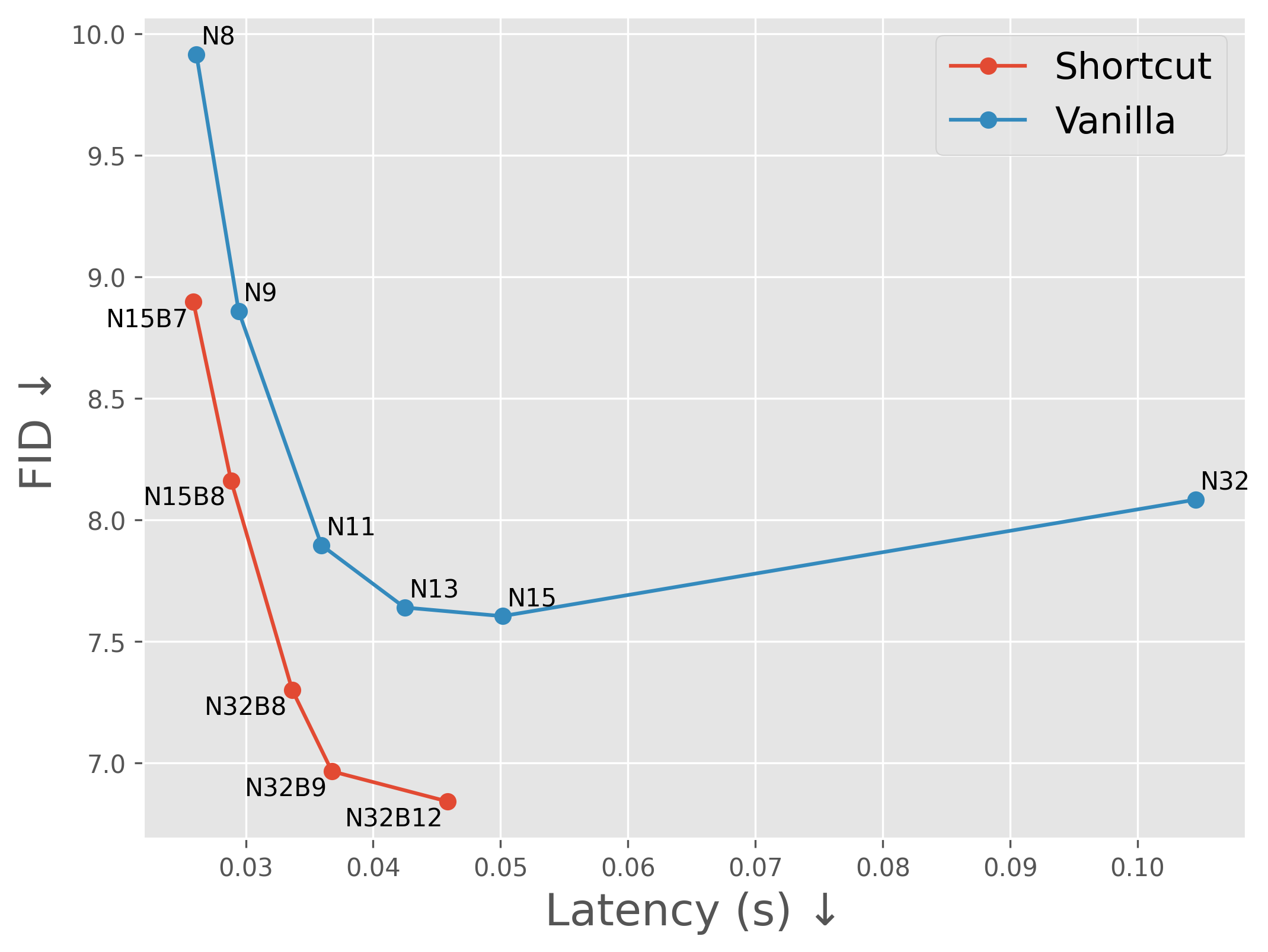
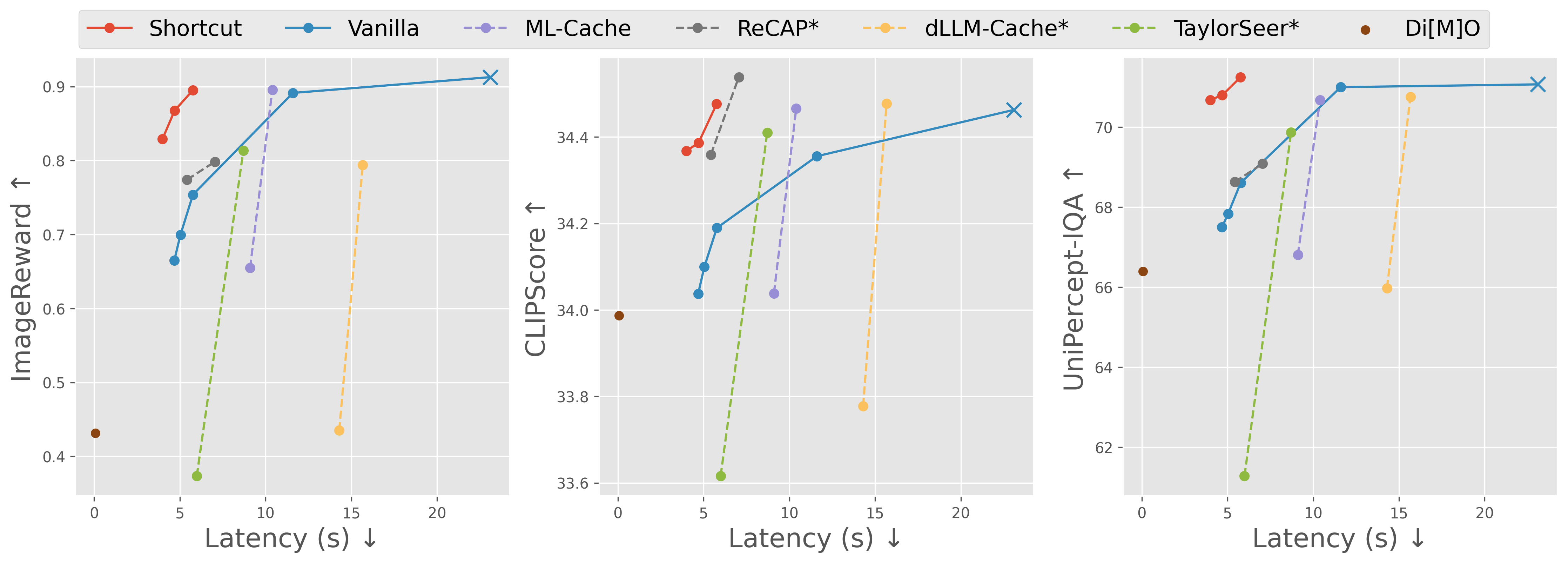
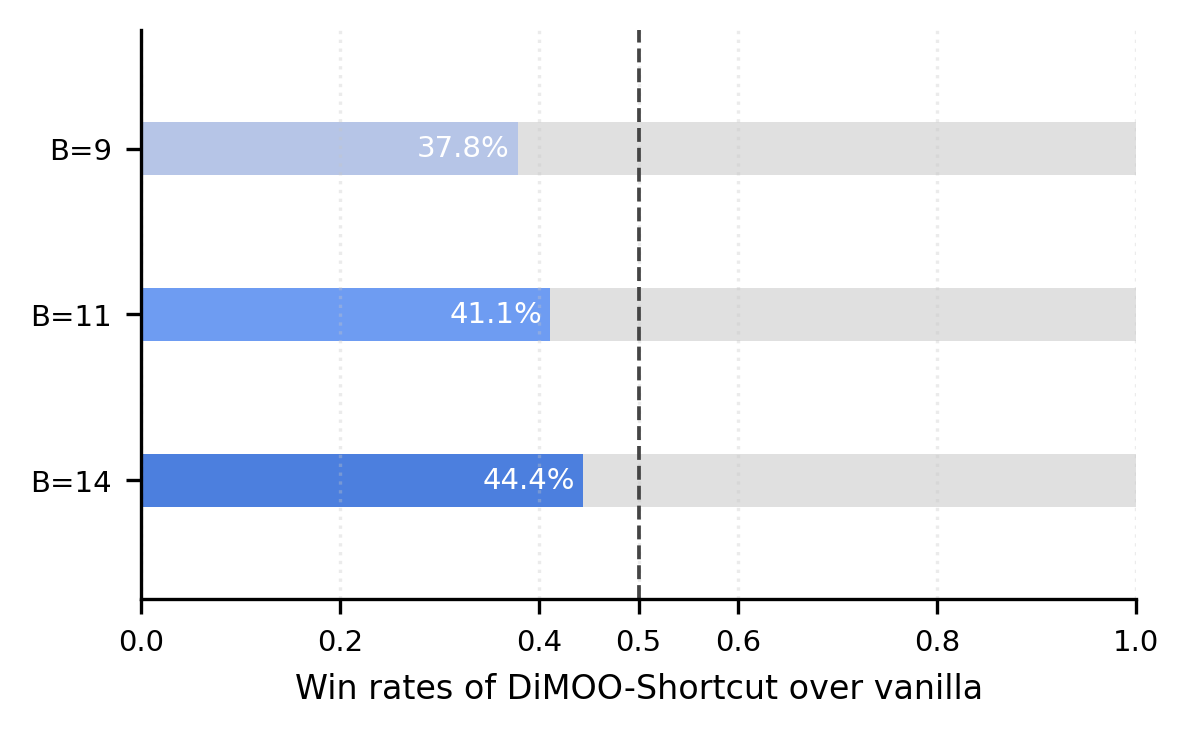
Observation 1: Feature trajectory is smooth
Assumption 1: It is feasible to predict the next feature from the current feature with light computation
Observation 2: Feature trajectory is controlled by sampled tokens
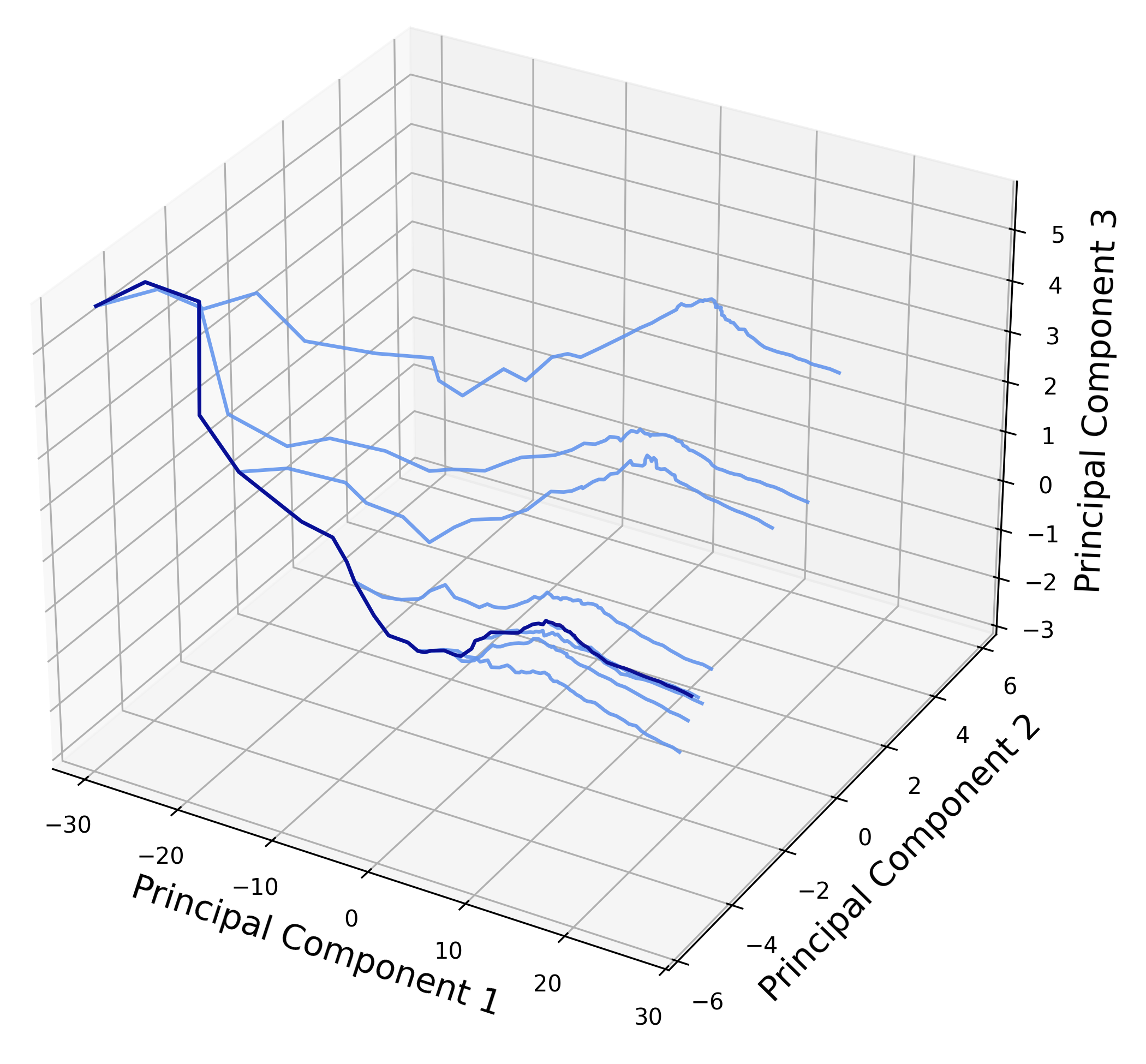
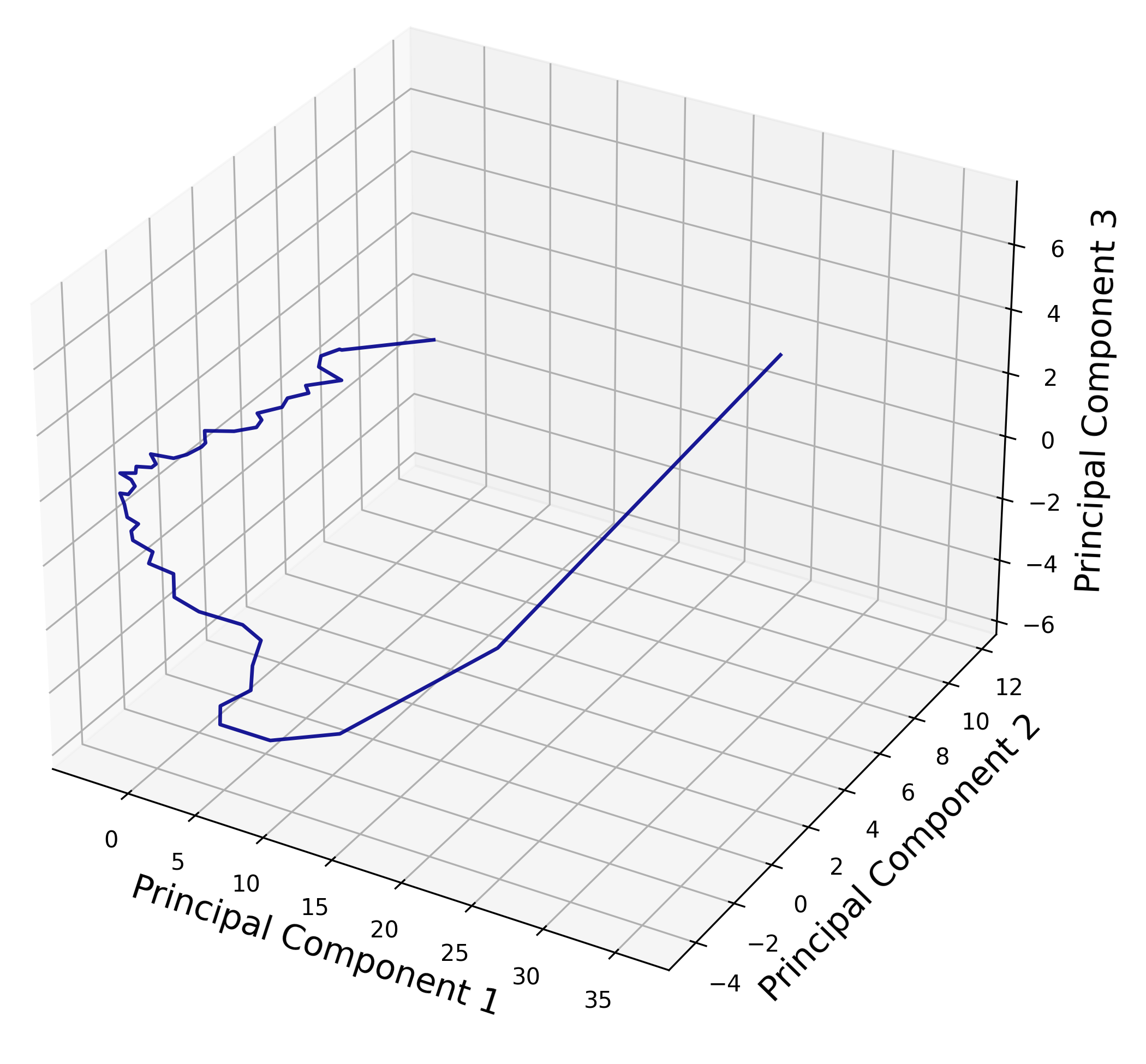
PCA visualization of feature trajectories generated with the same prompt and initial random seed. Left: Using a MIGM, we first generate a trajectory (the dark one) and then change the random seed at intermediate steps to generate more samples (the light ones). The randomness in sampling tokens greatly affects the generation process. Right: In contrast, for continuous diffusion with ODE sampling, trajectories generated from the same starting point are always the same, without randomness at intermediate steps.